Dangers of Sequential IDs
IDs sometimes need to be made public - be it for use in links, WebAPI requests, or in-app referencing. For a long while now I kept telling everyone around to avoid sequential IDs if possible. And in this blog post I aim to explain why.
Why Sequential IDs are evil
Imagine a website that allows users to upload some files or data. Once user uploads the file/data, the website tells the user “hey, now you can access your stuff at totallysecretfilesspace.com/file/abcdef. Cool, right? The user can now access the file anywhere and even share it.
Now the person changes the link in their browser just by one letter - totallysecretfilesspace.com/file/abcdee. A different file opens, uploaded by someone else just a few seconds before.
Now, severity of this may vary. Most likely this file is not useful to anyone but the uploader. But on the other hand, the uploader might not know the danger - and upload something secret, like their passwords. Yes, no one should ever do it - but we know that in practice people don’t concern themselves with security as much as they should.
A live example
For an example I’ll use the website used by a popular screenshot tool LightShot - prnt.sc.
I use LightShot daily - I just don’t upload the screenshot automatically. But for this example I took a screenshot and clicked upload. It gave me the following link: http://prntscr.com/u4f4ih. Now I change the ID in the link by one letter, and suddenly have someone’s screenshot of YouTube: https://prnt.sc/u4f4ig.
YouTube screenshot isn’t dangerous, but as I mentioned earlier, people tend to upload screenshots of very personal nature.
A live example - a step further
I also wrote a simple tool for browsing LightShot to serve as example. All of its source code can be viewed on GitHub: https://github.com/TehGM/Prnt.sc-Viewer.
Why did I write this? To show how simple it is. The initial workable (if buggy) version of the tool was ready within 2 or 3 hours - and most of the time I spent on figuring out WPF quirks (as I don’t usually work with WPF).
In fact, only 2 files of the entire tool are really needed: ScreenshotID.cs which deals with incrementing and decrementing non-number ID by one, and ScreenshotDownloadingExtensions.cs which makes requests to prnt.sc website. And that’s it - all other files are just fancy wrappers and logic for displaying the content on screen.
This really shows that semi-automating (or even full-automating) the scrapping of sequential ID-based web applications is so easy, so virtually anyone can do it.
Alternatives
Now you might ask how to deal with the problem. I shall suggest some potential solutions:
Proper Authorization
One of the best options isn’t really an alternative to sequential IDs, but rather a mechanism that will reduce or completely remove risks I mentioned before - implementing proper authentication and authorization.
To view uploaded content, the user has to login, and needs to have proper permissions granted by the uploader.
Of course this solution requires some effort to implement the security. In addition, granting permissions is a manual task - something users might be not happy about. Still this remains the most secure option.
GUIDs
The first alternative to sequential IDs is really simple - use GUIDs (UUIDs). They’re designed to be unique, and as such, are generally not sequential (at least not in increment-by-one meaning). They unfortunately are long, so aren’t great for links.
Encoding GUID bytes (for example using Base64) works well for making them much shorter. For most use cases it’ll be perfect - it won’t be a sequential ID, and well usable for links - think YouTube video links. Mads Kristensen posted a great example on his blog - make sure to check it out!
As an experiment I tried reducing the length of GUID even further by calling C#’s GetHashCode(). Of course I expected collisions to occur, but they started happening way faster than I expected - at around 400k GUIDs generated, collisions were very frequent.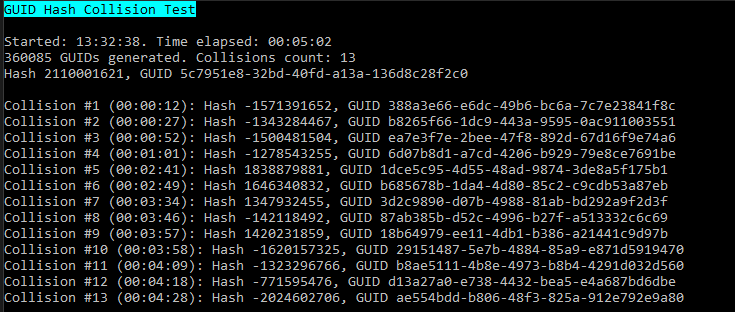
Timestamp
For content that isn’t generated frequently, using Timestamp (C# example: DateTime's Ticks property) can work well. Collision chance won’t be really high in such small infrequently used applications. The code would also be really simple: DateTime.UtcNow.Ticks.ToString("x").
However DateTime ticks might not be ideal for any kind of distributed systems that are used a lot by users - in such applications, collision chance is real. For that reason I’d personally advise against this, but YMMV.
Hashids
After researching GUIDs, I came across a cool looking library called Hashids. It takes secret seed and number as input, and generates non-sequential string ID. You can also reverse it back into a number. Because it uses secure seed, it’s not so trivial to determine order of IDs.
With this library, you can store normal (even sequential) IDs in database, while providing non-sequential string IDs publicly.
But Sequential IDs aren’t always evil!
You might shout this in response to this post. And you’d be absolutely right!
Sequential IDs are okay if you’re using proper authentication and authorization - since you’re checking who accesses the content anyway, IDs being predictable doesn’t matter much.
They also are okay if the content is never sensitive. Of course it might be hard to ensure this when content is user-provided - but make sure they’re very well aware that any content they upload will be public!
And in fact, even if IDs are non-sequential, it’s worth pointing that out to users. If you aren’t using proper permissions and authorization, any public link content is well… public. With little luck (or some brute-force), anyone will be able to find it.